
Understanding Attentive Recurrent Comparators
Aug 28 2017 - I recently came across an ICML’17 paper “Attentive Recurrent Comparators” which proposes a simple yet powerful model for data efficient learning. The paper presents the first super-human One-shot Classification performance on the Omniglot dataset using only raw pixel information! In this blog post I am going to present my understanding of the main ideas of the paper. The authors of the paper also released an implementation using Theano. But I found the implementation a bit difficult to follow. So as an exercise I actually went ahead and re-implemented it in PyTorch. Code at https://github.com/sanyam5/arc-pytorch
 ARC comparing two similar characters from the Omniglot dataset. The ARC uses an attention mechanism to look back and forth between the two images and judge their similarity. Source: My ARC implementation
ARC comparing two similar characters from the Omniglot dataset. The ARC uses an attention mechanism to look back and forth between the two images and judge their similarity. Source: My ARC implementation
Motivation
Data-efficient machine learning is the buzz phrase right now. The idea is to design ML algorithms that perform well but don’t require 100’s of thousands of annotated data points. An ideal ML algorithm would require just one data point to learn an entire concept. Such a concept learning system is said to be a One-shot Learning system. The challenge with doing One-shot Learning is due to the difficulty in having Dynamic Representations.

Imagine a system trained on images of buildings, cars and animals. If the new concepts of fruits and faces are introduced, the current feature set consisting of wheels, fur, windshield, trunk etc., are virtually useless to identify them. The authors call the representations that are formed by observing a fixed set of features Static Representations. It is clear that the current feature set must evolve to include features that can recognize the new entities. Ideally, the model should be in control of what features it observes and how lower-level features combine to form higher-level features. The authors call the representations formed by observing a continually evolving set of features Dynamic Representations.
Dynamic Representations
Dynamic Representation is basically coming up with a feature set on the fly, lazily. When you see an apple — you start thinking of its color, shape. When you see a face — you start thinking about color of eyes, shape of the nose, etc. One clever way of having Dynamic Representations is by encoding a given sample in the context of other samples. For example:
- When asked to differentiate between fruits like Apple, Orange, Guava, you try to form a representation of one fruit in terms of all others: How is Apple different from Orange and Guava?
- Similarly, when asked to differentiate between faces, you try to understand how is Face A different from other faces in the dataset.
ARCs
The paper first presents a simple model — “Attentive Recurrent Comparators” (ARCs) — for learning to differentiate between two given images. The model derives its motivation by observing how humans find points of difference between two given images.
 “Spot the difference”. Source https://commons.wikimedia.org/wiki/File:Spot_the_difference.png
“Spot the difference”. Source https://commons.wikimedia.org/wiki/File:Spot_the_difference.png
A human trying to differentiate between pair of images will not try to understand everything about the first image before taking a look at the second image. It’s just too much data to process all at once, most of which will be irrelevant to the task. The human instead takes alternating looks to understand what to look at.
You might see something in the first image simply because it is not present in the other image or vice versa. ARCs incorporate this aspect into them by using attention. The Attention mechanism opens a pathway for the Neural Networks to “ask” for a portion of the data.
The ARC architecture makes a clever use of the attention mechanism. At every time step it takes “glimpses” alternating between the first image (Image A) and the second image (Image B) similar to the way a human doing ‘Spot The Difference’.
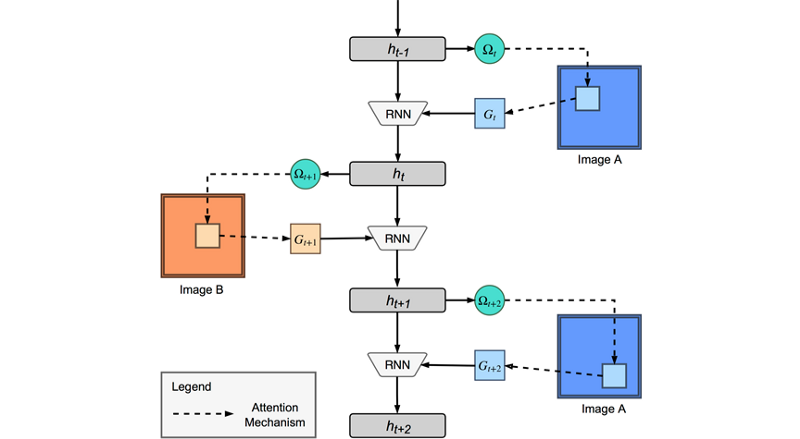 Source: Attentive Recurrent Comparators, ICML’17
Source: Attentive Recurrent Comparators, ICML’17
At the heart of ARC is a “controller” which is basically a Recurrent Neural Network (RNN) which at every time step t, in its current hidden state h(t-1) takes as input a glimpse G(t) and moves to a new hidden state h(t). The way this glimpse is generated is interesting. A small Neural Network (not shown in the diagram) converts h(t-1) to omega(t). The omega(t) are what the paper calls the “glimpse parameters”. The omega(t) can be thought of as a tuple (x, y, delta) from which a glimpse centered at (x, y) and with a zoom factor of delta.
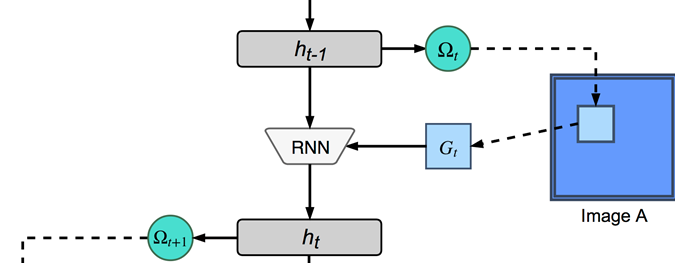 Attention Mechanism
Attention Mechanism
But, there is more to it. For a Neural Network to learn through gradient descent all functions used by it must be smooth (differentiable). It does not suffice to just crop a portion of the image and feed it as the glimpse. Soft or differentiable attention is used in modern Deep Learning for generating pixels of the glimpse by taking a weighted sum of ALL pixels in the image. The weights smoothly decay as one moves away from the pixels that the glimpse is trying to encode. The paper proposes using Cauchy decay kernels instead of the traditional Gaussian kernels. The reason for this choice is that Cauchy kernel is smoother than the Gaussian kernel (which decays too fast) and Neural Network learn smoother functions faster.
Though the RNN controller now has full control over where to focus it comes at the cost of “pixelating” if it tries to see larger regions. This is because the number of pixels in the glimpse are fixed and less than the number of pixels in the given image. The RNN controller must carefully choose what to see.
ARC Binary Classifier
So we have defined the architecture of ARCs. Let’s test it out on the simple binary classification task as a sanity check.
How about we take the final hidden state H(T) as these encodings and feed them to a simple Neural Network whose task would be to tell if the two images belong to the same class or not? Virtually any dataset with independant classes can be used for this type of training.This paper specifically uses the Omniglot and the CASIA Webface datasets.
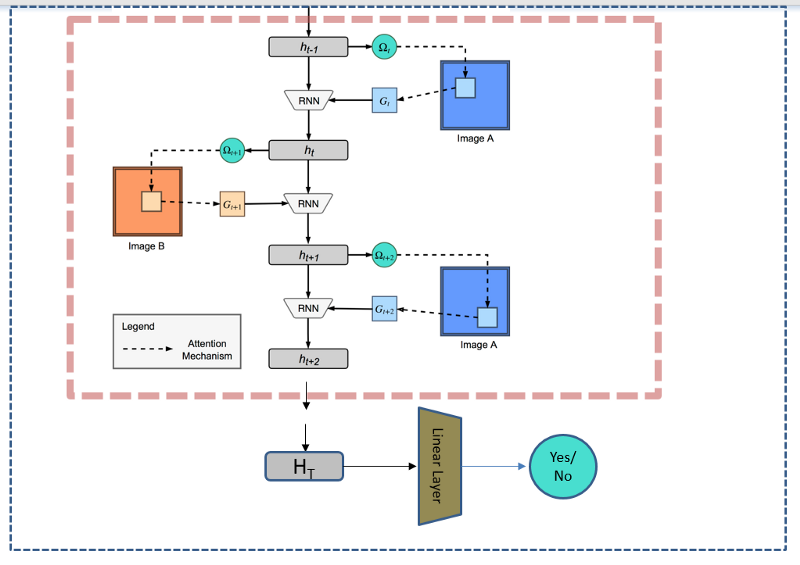 Feeding the encoding H(T) from ARC ( in red dotted box) to Linear Layer Classifier
Feeding the encoding H(T) from ARC ( in red dotted box) to Linear Layer Classifier
The Omniglot data-set has alphabets from 50 languages and the challenge is to use only 30 of them for training and validation and test on the 20. This means the network must learn to differentiate between characters it has never even seen. At the risk of slight exaggeration, it’s like letting a Neural Network train on images of various types of Animals, various types of Cars and various types of Buildings and then giving it two different photos of two different fruits (which may or may not belong to the same species) expecting it to correctly predict whether they belong to the same species or not!
When I put to train my PyTorch implementation of the ARCs , it worked liked a charm. It was so much fun to visualize the attention mechanism at work.


Attention focuses on seemingly similar areas of dissimilar characters. Source: https://github.com/sanyam5/arc-pytorch.


Attention flawlessly comparing corresponding portions in two images. Source: https://github.com/sanyam5/arc-pytorch
One-shot Learning
Okay, so how does this all tie back up to One-Shot Learning?
Well, we said we wanted ARCs to learn to encode images of an Apples in terms of images of Oranges and Guava. We want ARCs to learn to encode one data point with respect to the other data points (Dynamic Representations).
To understand how the authors use ARCs to achieve this, its first necessary to concretely define the objective. The paper’s main result is on the Omniglot One-shot Classification task, detailed below :
-
Omniglot dataset contains characters from 50 alphabets or languages. Each language has variable number of characters. All characters in a language are drawn by 20 different individuals. Totally there are 1623 characters in the dataset.
-
You may use 30 of 50 languages for training and validation. (Connecting back to our analogy, this would be equivalent of doing training on various types of Animals, various types of Cars and various types of Buildings)
-
After training, the network is given a background set which contains just ONE image each for 20 characters in a language chosen at random from the remaining 20 languages. (Connecting this back to our analogy, the remaining 20 “languages” (classes) could be {Fruits, Faces, Tables, Chairs, etc}. Suppose the “language” chosen at random is Fruits then a background set would contain just one image of an apple, just one image of an orange, just one image of guava and so on.)
-
The network must now correctly classify a given test image T as belonging to the same class as one of the 20 characters whose images were given as the background set. (Connecting this back to our analogy, the test image could be different image of apple, or a different image of orange, etc. and the network must correctly classify it as an apple, orange, guava, etc..)
The paper proposes 2 different models based on ARCs for One-shot Learning.
Naive ARC Model
Do pair-wise comparison of image T to every other image in the background-set and train a Linear layer (shown in purple in the image) to compute a similarity score (shown as grey circles at the very bottom of the image) very similar to the way we constructed the Binary ARC classifier. And then classify the image T as belonging to the class for which the score is maximum.
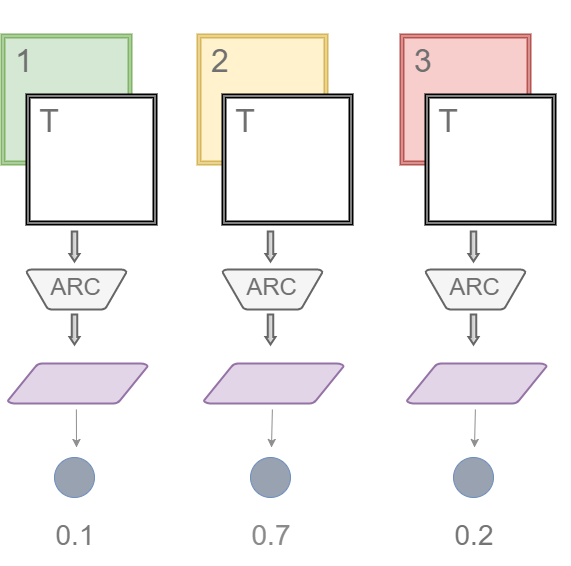
This model is dead simple and it even gives decent results but there is just one tiny problem — consider you have only seen spherical fruits all your life, it probably doesn’t occur to you that shape of the fruit might be an important feature in classifying a fruit. We converted the pairwise encodings immediately into scores without considering what other features were considered while generating other pair-wise comparisons.
Let’s take an example. Let’s suppose that Image 1 = Apple, Image 2 = Orange, Image 3 = Guava. Assume that both Orange and Guava are spherical while Apple has a different shape. Assume that T is an another image of Orange which also has leaves attached to it on the top. Here’s what would happen
T vs. Image 1 (Apple)
- Color: Orange vs. Red(0.2/1), Shape is Different (0.2/1). Score of 0.4/2
T vs. Image 2 (Orange)
- Leaves on top: Yes vs. No (0/1), Shape is slightly different (0.9/1). Score of 0.9 / 2
T vs. Image 3 (Guava)
- Color: Orange vs. Green (0.2/1), Shape is slightly different (0.9/1). Score of 1.1 / 2
What just happened!!! We just classified an image of an Orange as a Guava solely because we failed to consider that color in T vs. Image 2 (Orange) could be an important feature too. This happened because both T and Image 2 were orange in color. The encoding from ARC did not take this to be a valid feature.
If we had instead combined encodings (or representations) from all pair-wise comparisons it would have been obvious that Color is an important feature.
21-way ARC
One could say that this problem arises because we chose to make just a 2-way ARC took a 2 images at time and glanced at them alternatingly. What if we made a 21-way ARC that took 21 images (20 background and 1 test) and cycled through them?
In theory this should work and we should be able to get a representation of T with respect to the entire background set. It would theoretically be possible to train the network by asking it to predict 20 Yes/No decisions instead of just 1 Yes/No decision as we did in the ARC Binary Classifier.
All we would need then is a Linear Layer that converts this encoding into 20 outputs for each class in the background set as the probabilities of T belonging to the corresponding classes.
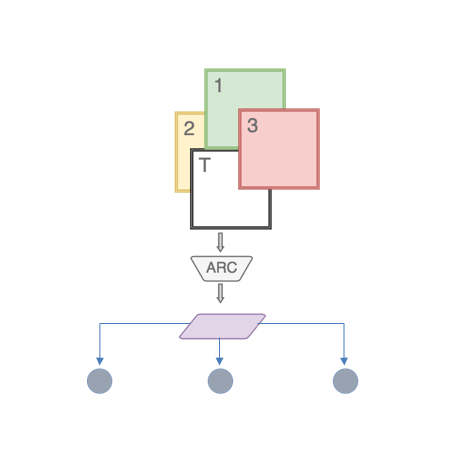
An example of a 4-way ARC, analogous to a 21-way ARC.
But unfortunately this will be just to much data for the RNN controller to digest. This especially because the memory requirements of the controller grow quadratically with the increasing number of input images.
Contextual ARC
So the authors make a compromise. They suggest making 20 pairwise comparisons and feeding these 20 encodings arranged in any order to Bi-directional LSTM (BD-LSTM). Think of BD-LSTM as a black box that can take information from these 20 pair-wise encodings, merge information from all these encodings and then finally output a 20 contextual encodings. These 20 contextual encodings can then be again mapped to pair-wise similarity scores as before (probabilities of T belonging to the corresponding class).
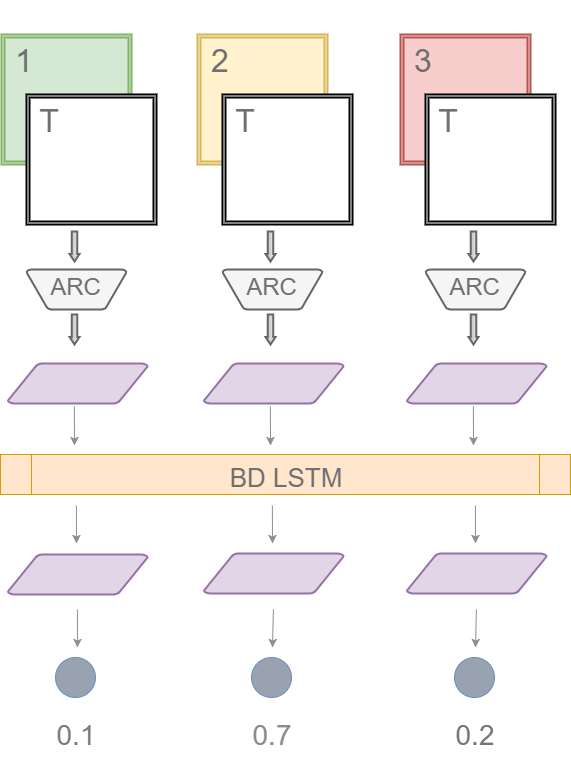
The BD-LSTM approach can potentially deliver better results because of its ability to reconcile the encodings from all 20 pair-wise comparisons.
Results
Using simple ARC based models the authors achieve first superhuman One-shot Classification performance on the Omniglot dataset with a model that uses just raw pixel data. The Naive ARC model that uses convolutional feature extractors achieves 97.75% and the Full Context variant gets 98.5%. It is remarkable given that human performance is at around 95.5%.
Conclusion
I think this really was a novel and simple approach with good results. This is also a positive step towards achieving true Dynamic Representations.
Hope you liked it! Please leave any comments below. Checkout my implementation of the ARCs at https://github.com/sanyam5/arc-pytorch
Note: I initially wrote this blog on Medium, here. But unfortunately, Medium has disabled embedding blogs so I had manually copy it here.