
I have joined Google’s Search team at it’s Bangalore office. I am working in areas related to Machine Learning and Natural Language Processing.
Before that, I was a Visiting Research Scholar at the Machine Learning and Perception lab at Georgia Tech led by Prof. Dhruv Batra. I work on Machine Learning problems at the intersection of vision and language. Prior to that I was on a research internship at the Statistics and Machine Learning Group at Indian Institute of Science, Bangalore. Before that I was working as a Platform Engineer at Soroco. I completed my Bachelor’s in Computer Science and Engineering from the Indian Institute of Technology Kharagpur in May 2016.
Select Awards / Honors
- Aug 2009 – NTSE Scholarship (National Talent Search Examination) by Department of Science and Technology, Government of India
- Awarded to less than 1% applicants based on their scholastic achievements.
- Aug 2011 – KVPY Fellow (Kishore Vaigyanik Protsahan Yojana Fellow) by Department of Science and Technology, Government of India
- Awarded to just ~100 students all over India with high academic potential.
- Sept. 2012 – Aditya Birla Scholarship by Aditya Birla Group
- Awarded to just 15 students all over the from the best engineering and management colleges of India.
- Feb 2013 – OP Jindal Engineering and Management Scholarship by OP Jindal Group
- Awarded to just 4 students from each of the few top-tier engineering and management colleges in India.
Publications
CVPR 2019 Workshop on Deep Learning for Semantic Visual Navigation
[pdf] / code(to be released soon)
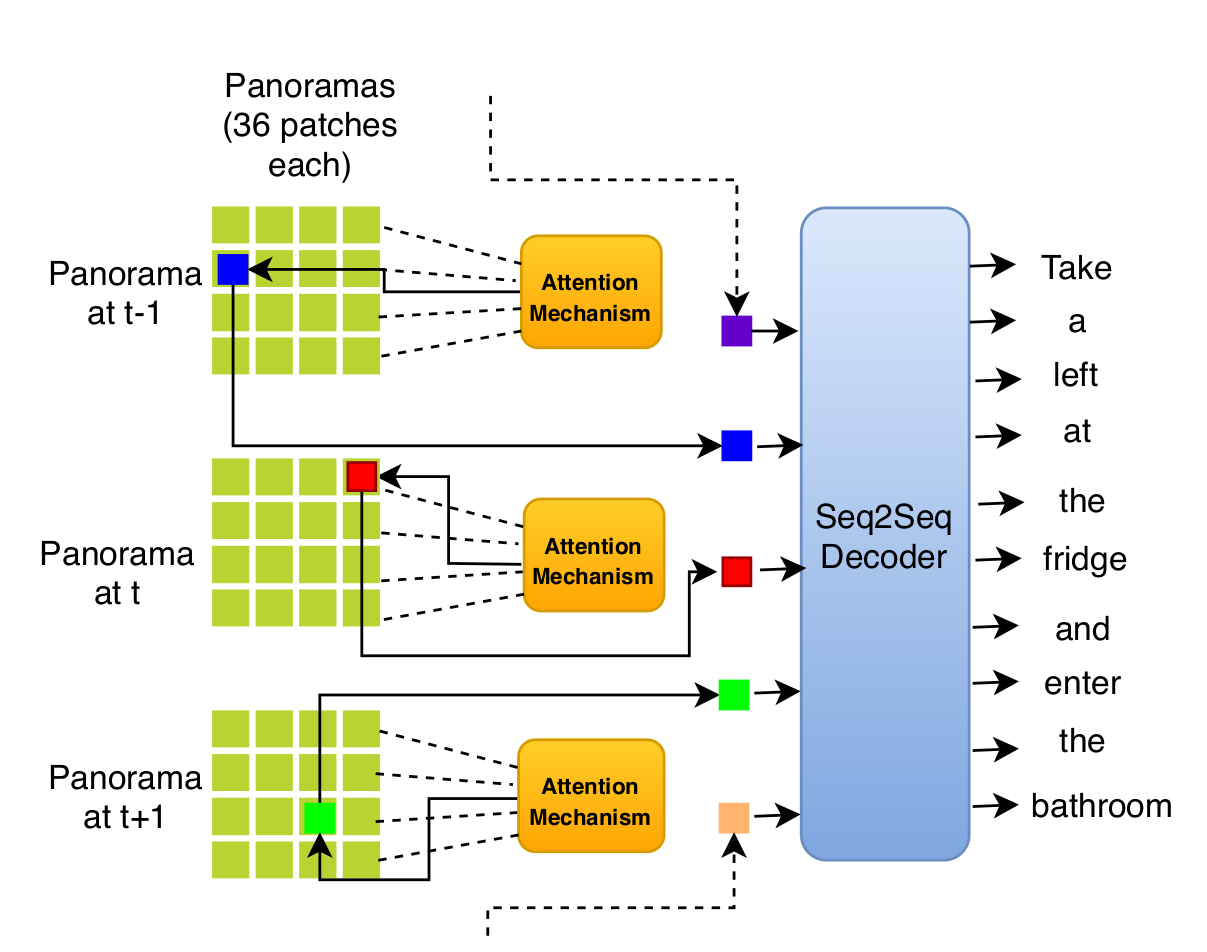
Instruction following for vision-and-language navigation (VLN) has prompted significant research efforts developing more powerful “follower” models since its inception. However, the inverse task of generating visually grounded instructions given a trajectory – or learning a “speaker” model – has been largely unexamined. We present a “speaker” model that generates navigation instructions in two stages, by first selecting a series of discrete visual landmarks along a trajectory using hard attention, and then second generating language instructions conditioned on these landmarks. This two-stage approach improves over prior work, while also permitting greater interpretability. We hope to extend this to a reinforcement learning setting where landmark selection is optimized to maximize a follower’s performance without disrupting the model’s language fluency.
Joint Conference on Digital Libraries (JCDL) 2017:6th International Workshop On Mining Scientific Publications
[pdf]

Patents
SYSTEMS AND METHODS FOR EXECUTING SOFTWARE ROBOT COMPUTER PROGRAMS ON VIRTUAL MACHINES
Publication number: 20180189093
Abstract: Techniques for executing one or more instances of a computer program using virtual machines, the computer program comprising multiple computer program portions including a first computer program portion. The techniques include determining whether an instance of any of the multiple computer program portions is to be executed; when it is determined that a first instance of the first computer program portion is to be executed, accessing first information specifying a first set of one or more virtual machine resources required for executing the first instance of the first computer program portion; determining whether any one of the plurality of virtual machines has at least the first set of virtual machine resources available; and when it is determined that a first of the plurality of virtual machines has the first set virtual machine resources available, causing the first virtual machine to execute the first instance of the first computer program portion.
Filed: January 5, 2018
Publication date: July 5, 2018
Inventors: Sanyam Agarwal, Rohan Narayan Murty, George Peter Nychis, Wolfgang Richter, Nishant Kumar Jain, Surabhi Mour, Shreyas H. Karanth, Shashank Anand
Select Projects

Room-to-Room dataset is a commond dataset used in several vision and language navigation tasks. The dataset contains real-world panoramic scans of building interiors provided my the Matterport3D dataset . An agent can choose to move in this 3D environment by taking actions. I optimized the original Room-to-Room simulator to use GPU for state update operations when the agent takes any actions. Combined with caching of repeated computations this resulted in a simulator that is 17x faster frame rate on a single GPU! Training time of most vision-and-language models can be brought down significantly using this simulator instead of the original simulator.

The paper improves upon the state-of-the art accuracy for counting based questions in VQA. They do it by enforcing the prior that each count corresponds to a well defined region in the image and is not diffused all over it. They hard-attend over a fixed set of candiate regions (taken from pre-trained Faster-R-CNN network) in the image by fusing it with the information from the question. They use a variant of REINFORCE - Self Critical Training - which is well suited for generating sequences.
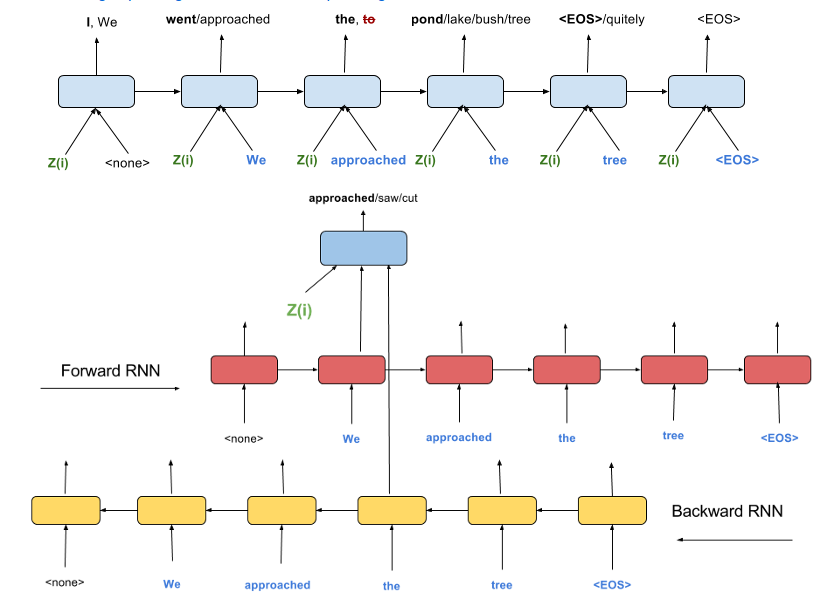
Skip-Thoughts uses the order of the sentences to “self-supervise” itself. The underlying assumption here is that whatever, in the content of a sentence, leads to a better reconstruction of the neighbouring sentences is also the essence of the sentence. The decoders are trained to minimise the reconstruction error of the previous and the next sentences given the embedding of current sentence. This reconstruction error is back-propagated to the Encoder which must now pack as much information about the current sentence that will help the Decoders minimise the error in generating the previous and next sentences.

Attentive Recurrent comparators state of the art performance in one-shot learning on the Omniglot dataset. The key idea is to make the training phase as close as possible to evaluation phase. Since the evaluation phase is comparitive, making the training phase also comparitive will lead to better generalization. In training, the model learns to compare between two randomly chosen images of either same or different characters.

Led the Artificial Intelligence team. Created a framework for learning robot control policies for playing soccer using Q-Learning. Our group won Bronze medal in FIRA 2015, South Korea.